Cinévoqué
Amarnath Murugan | Amal Dev | Jayesh Pillai

This project started out as a storytelling concept in 2017, as an extension to the research work on grammar of VR storytelling by Prof. Jayesh Pillai. The project took its shape with Amarnath and Amal’s summer internship project in 2018. The framework and the experiences built with it has been presented at multiple national and international conferences, which are listed below.
Abstract
The grammar of storytelling in Cinematic Virtual Reality (CVR) is still evolving and is not as established as traditional movies due to its immersive nature. Unlike traditional films where the director decides the framing of the visuals shown, in CVR, the viewers have control over the point of view (POV). As a result, they are likely to miss important events in the narrative by focusing elsewhere in the virtual environment. In our framework, Cinévoqué, we take advantage of this feature to present an experience that tries to maintain consistency in the narrative seen by the viewer. It achieves this by following the viewer’s gaze and the events in the film that it intersects with; if they miss an event that’s pertinent to the rest of the storyline, the framework shifts to an alternate storyline that does not have said event as a presupposition. The transition takes place unbeknownst to the viewer so as not to interrupt the flow of the experience.
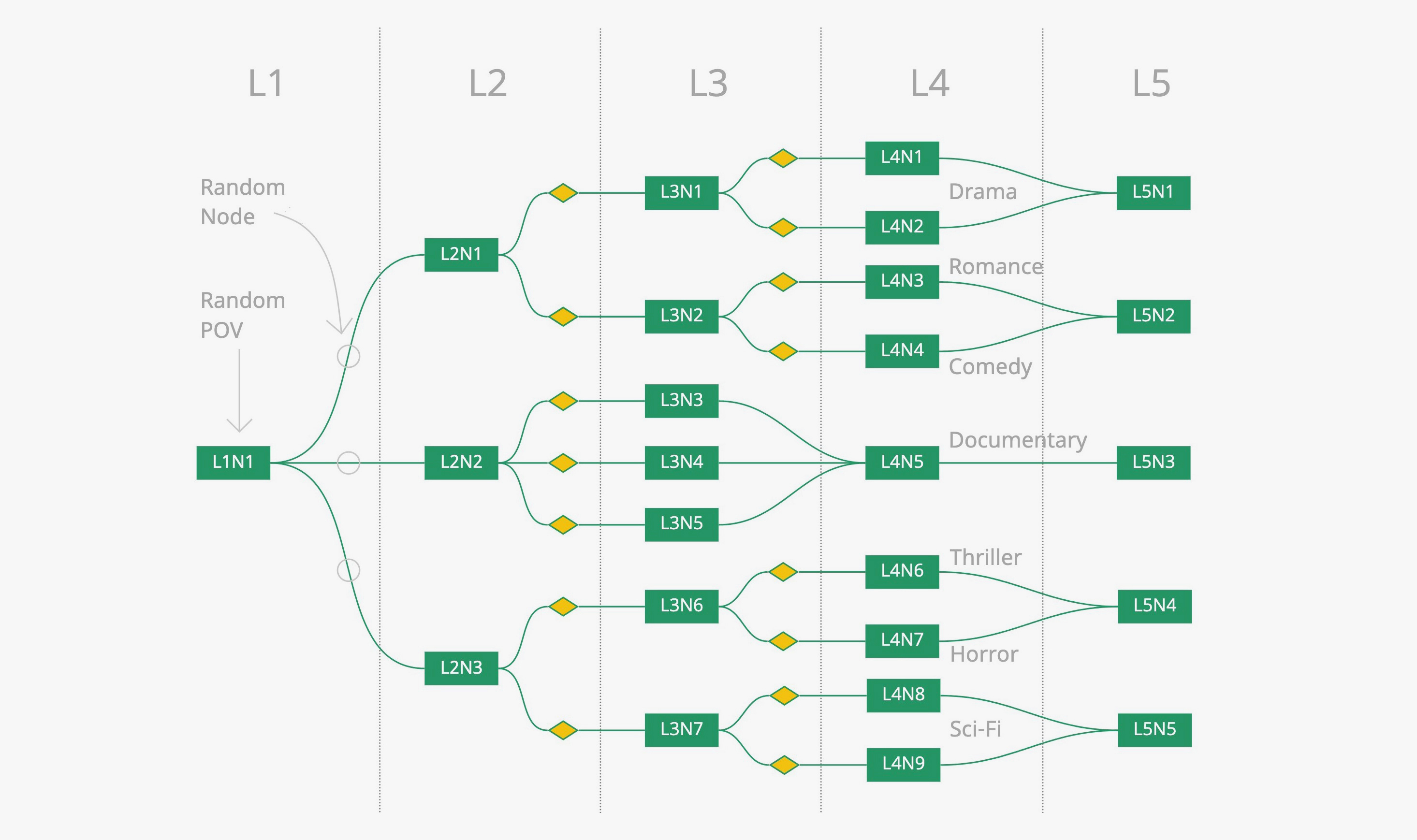
Cinévoqué is built for live-action CVR since real-time 3D experiences have the affordance of the framework implicitly. The novelty of this work lies in its intent to bring passive interactivity to an experience composed of live-action videos that are mostly immutable in real-time. Furthermore, adding a layer of real-time changes to live-action VR films allows for new use cases that were not previously possible. For example, the experiences “Schrödinger’s Vada-Pav” and “Till We Meet Again” that was built with Cinévoqué have a virtual body that rotates to align with the user’s physical body using 6DOF controller data. Similarly, other data can be used to influence the visuals and audio in the experience.
Outcomes
This project yielded three films and publications. We also presented our work at five conferences in total.
Films / Narratives



Schrödinger’s Vada-Pav was the first film made with Cinévoqué. It had the simplest narrative structure for a multi-storyline film, with two possible endings. The story goes as follows: Schrödinger(viewer) is in his office watching a video on Schrödinger’s cat, and he orders a Vada-Pav (a local Indian snack), when the waiter brings the order he knocks on the office door and peeks in. Depending on the viewer turning back to look at him, the Vada-pav is delivered or isn’t. This exploration made the challenges involved in shooting such a film apparent and also helped us think of improvements and changes to the initial framework.
Shapeshifter is a relatively complex film built to test the limitations of the framework post Schrödinger’s Vada-Pav. The experience had four possible storylines. The film’s setting was that three people (including the viewer) were stuck in an office during an invasion by a shape-shifting alien species. Depending on the details the viewer sees, the ending could reveal one of the three as an alien or show an alien entering the office. The framework version used for this had many limitations; it did not support stereo video and spatial audio, and it also needed improvements in handling transitions.
Till We Meet Again was our first attempt at creating a film meant for public viewing. It is a stereoscopic 3D film that has eight possible storylines with different genres. It incorporated the learnings from the previous films and built with improvements to the frameworks. This film was presented as a demo at VRCAI 2019 in Brisbane, Australia.
Publications
-
Pillai J.S., Murugan A. and Dev A. (2019). “Till We Meet Again: A Cinévoqué Experience (Demo)”, in: 17th ACM SIGGRAPH International Conference on Virtual Reality Continuum and Its Applications in Industry (VRCAI) 2019, Brisbane, Australia.
-
Murugan A., Dev A., and Pillai J.S. (2019). “Cinévoqué: Development of a Passively Responsive Framework for Seamless Evolution of Experiences in Immersive Live-Action Movies”, in: The 25th ACM Symposium on Virtual Reality Software and Technology, Sydney, Australia.
-
Pillai J.S., Murugan A. and Dev A. (2019). “Cinévoqué: Design of a Passively Responsive Framework for Seamless Evolution of Experiences in Immersive Live-Action Movies”, in: 17th IFIP TC.13 International Conference on Human-Computer Interaction – INTERACT 2019, Paphos, Cyprus.
Invited Talks
We were invited to speak about Cinévoqué at Unite India 2018, third ACM SIGCHI Asian Symposium and IndiaHCI 2019.

